
1.1 进程与线程
1.1.1 进程和线程的基本概念
进程:进程是系统进行资源分配和调度的一个独立单位,是系统中的并发执行的单位。
线程:线程是进程的一个实体,也是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,有时又被称为轻权进程或轻量级进程。
1.1.2 进程与线程的区别?
进程是资源分配的最小单位,而线程是CPU调度的最小单位;
创建进程或撤销进程,系统都要为之分配或回收资源,操作系统开销远大于创建或撤销线程时的开销;
不同进程地址空间相互独立,同一进程内的线程共享同一地址空间。一个进程的线程在另一个进程内是不可见的;
进程间不会相互影响,而一个线程挂掉将可能导致整个进程挂掉;
1.1.3 为什么有了进程,还要有线程呢?
进程可以使多个程序并发执行,以提高资源的利用率和系统的吞吐量,但是其带来了一些缺点:
1.进程在同—时间只能干 一 件事情;
⒉进程在执行的过程中如果阻塞,整个进程就会被挂起,即使进程中有些工作不依赖与等待的资源,仍然不会执行。
基于以上的缺点,操作系统引入了比进程粒度更小的线程,作为并发执行的基本单位,从而减少程序在并发执行时所付出的时间和空间开销,提高并发性能。
1.1.4 进程的状态转换
进程包括三种状态:就绪态、运行态和阻塞态。
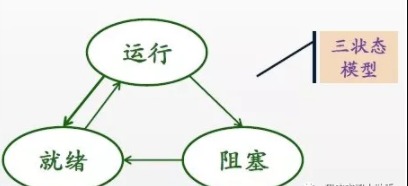
就绪一>执行:对就绪状态的进程,当进程调度程序按一种选定的策略从中选中一个就绪进程,为之分配了处理机后,该进程便由就绪状态变为执行状态;
执行一>阻塞:正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态,如进程提出输入/输出请求而变成等待外部设备传输信息的状态,进程申请资源(主存空间或外部设备)得不到满足时变成等待资源状态,进程运行中出现了故障(程序出错或主存储器读写错等)变成等待干预状态等等;
阻塞—>就绪:处于阻塞状态的进程,在其等待的事件已经发生,如输入/输出完成,资源得到满足或错误处理完毕时,处于等待状态的进程并不马上转入执行状态,而是先转入就绪状态,然后再由系统进程调度程序在适当的时候将该进程转为执行状态;
执行一>就绪:正在执行的进程,因时间片用完而被暂停执行,或在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行而被迫让出处理机时,该进程便由执行状态转变为就绪状态。
1.1.5 进程之间的通信方式以及优缺点
管道(PIPE)
1.有名管道:一种半双工的通信方式,它允许无亲缘关系进程间的通信
- 优点:
- 可以实现任意关系的进程间的通信
- 缺点:
- 长期存于系统中,使用不当容易出错
- 缓冲区有限
2.无名管道:一种半双工的通信方式,只能在具有亲缘关系的进程间使用(父子进程)
- 优点:
- 简单方便
- 缺点:
- 局限于单向通信
- 只能创建在它的进程以及其有亲缘关系的进程之间
- 缓冲区有限
信号量(Semaphore)
信号量(Semaphore):一个计数器,可以用来控制多个线程对共享资源的访问
- 优点:
- 可以同步进程
- 缺点:
- 信号量有限
信号(Signal)
信号(Signal):一种比较复杂的通信方式,用于通知接收进程某个事件已经发生
消息队列(Message Queue)
消息队列(Message Queue):是消息的链表,存放在内核中并由消息队列标识符标识
- 优点:可以实现任意进程间的通信,并通过系统调用函数来实现消息发送和接收之间的同步,无需考虑同步问题,方便
- 缺点:信息的复制需要额外消耗 CPU 的时间,不适宜于信息量大或操作频繁的场合
共享内存(Shared Memory)
共享内存(Shared Memory):映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问
- 优点:
- 无须复制,快捷,信息量大
- 缺点:
- 通信是通过将共享空间缓冲区直接附加到进程的虚拟地址空间中来实现的,因此进程间的读写操作的同步问题
- 利用内存缓冲区直接交换信息,内存的实体存在于计算机中,只能同一个计算机系统中的诸多进程共享,不方便网络通信
套接字(Socket)
套接字(Socket):可用于不同计算机间的进程通信
- 优点:
- 传输数据为字节级,传输数据可自定义,数据量小效率高
- 传输数据时间短,性能高
- 适合于客户端和服务器端之间信息实时交互
- 可以加密,数据安全性强
- 缺点:
- 需对传输的数据进行解析,转化成应用级的数据。
1.1.6 线程之间的通信方式
● 锁机制:包括互斥锁/量(mutex)、读写锁(reader-writer lock)、自旋锁(spin lock)、条件变量(condition)信号量:提供了以排他方式防止数据结构被并发修改的方法。
○ 读写锁(reader-writer lock):允许多个线程同时读共享数据,而对写操作是互斥的。
○ 自旋锁(spin lock)与互斥锁类似,都是为了保护共享资源。互斥锁是当资源被占用,申请者进入睡眠状态;而自旋锁则循环检测保持者是否已经释放锁。如果别的线程长时期占有锁,那么自旋就是在浪费CPU做无用功,但是自旋锁一般应用于加锁时间很短的场景,这个时候效率比较高。条件变量(condition):可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。互斥锁一个明显的缺点是他只有两种状态:锁定和非锁定。而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,他常和互斥锁一起使用,以免出现竞态条件。当条件不满足时,线程往往解开相应的互斥锁并阻塞线程然后等待条件发生变化。一旦其他的某个线程改变了条件变量,他将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。总的来说互斥锁是线程间互斥的机制,条件变量则是同步机制。
● 信号量机制(Semaphore)无名线程信号量
○ 命名线程信号量● 信号机制(Signal):类似进程间的信号处理
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制
1.1.7 进程之间私有和共享的资源
● 私有:地址空间、堆、全局变量、栈、寄存器
● 共享:代码段,公共数据,进程目录,进程 ID
1.1.8 线程之间私有和共享的资源
● 私有:线程栈,寄存器,程序计数器
● 共享:堆,地址空间,全局变量,静态变量
1.1.9 多进程与多线程间的对比、优劣与选择
对比:
| 对比维度 | 多进程 | 多线程 | 总结 |
|---|---|---|---|
| 数据共享、同步 | 数据共享复杂,需要用 IPC;数据是分开的,同步简单 | 因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 | 各有优势 |
| 内存、CPU | 占用内存多,切换复杂,CPU 利用率低 | 占用内存少,切换简单,CPU 利用率高 | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 线程占优 |
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 | 适应于多核分布式 | 进程占优 |
优劣:
| 优劣 | 多进程 | 多线程 |
|---|---|---|
| 优点 | 编程、调试简单,可靠性较高 | 创建、销毁、切换速度快,内存、资源占用小 |
| 缺点 | 创建、销毁、切换速度慢,内存、资源占用大 | 编程、调试复杂,可靠性较差 |
选择:
● 需要频繁创建销毁的优先用线程
● 需要进行大量计算的优先使用线程
● 强相关的处理用线程,弱相关的处理用进程
● 可能要扩展到多机分布的用进程,多核分布的用线程
● 都满足需求的情况下,用你最熟悉、最拿手的方式
二 网络基础
2.1 TCP和UDP
2.2 HTTP和HTTPS
介绍HTTP协议的格式
HTTP(Hypertext Transfer Protocol)协议是用于在Web中传输数据的应用层协议。HTTP协议的基本格式如下
请求报文格式:
Method Request-URI HTTP-VersionHeader1Header2Header3Header...
Body● Method:请求方法,例如GET、POST、PUT、DELETE等。
● Request-URI:请求资源的统一资源标识符(URL),指定了要访问的资源路径。
● HTTP-Version:HTTP协议版本号,通常是”HTTP/1.1”或”HTTP/2.0”。
● Headers:包含请求的各种头信息,如User-Agent、Host、Accept等,以键值对的形式表示。
● Body:POST请求时可能包含请求的实体主体,用于传输数据。GET请求没有请求主体。
说明:说明:请求行三个字段之间以“空格”分割,首部字段是通过换行符(CRLF,即回车符+换行符)来进行分隔的,因为Header的个数不确定,所以最后一个Header的后边用一个空行来表示Header的结束。
响应报文格式:
HTTP-Version Status-Code Reason-PhraseHeader1Header2Header3Header...
Body● HTTP-Version:HTTP协议版本号,与请求报文中的一样。
● Status-Code:表示请求处理的结果状态码,例如200表示成功,404表示资源未找到,500表示服务器内部错误等。
● Reason-Phrase:对状态码的简短描述。
● Headers:包含响应的各种头信息,如Server、Content-Type、Content-Length等,以键值对的形式表示。
● Body:响应报文的实体主体,用于传输响应数据。比如,对于HTML页面或JSON数据等。
说明:状态行三个字段之间以“空格”分割,首部字段是通过换行符(CRLF,即回车符+换行符)来进行分隔的,因为Header的个数不确定,所以最后一个Header的后边用一个空行来表示Header的结束。
示例
#####请求消息#####GET /index.html HTTP/1.1Host: www.example.comUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36Accept: text/html,application/xhtml+xml
#####响应消息#####HTTP/1.1 200 OKServer: Apache/2.4.41 (Unix)Content-Type: text/html; charset=utf-8Content-Length: 1270
<!DOCTYPE html><html><head> <title>Welcome to Example.com</title></head><body> <h1>Hello, World!</h1></body></html>HTTP中GET和POST请求方法的区别
在HTTP(Hypertext Transfer Protocol)中,GET和POST是两种常用的请求方法,用于向服务器发送请求。它们有以下区别:
1.传输方式:
a. GET:通过URL传输数据,在URL中可以看到参数和其对应的值。数据附加在URL后面,以问号**?分隔,参数之间用&**连接。因为数据暴露在URL中,所以不适合传输敏感信息或大量数据。
b. POST:通过HTTP请求的消息体传输数据,不会将数据暴露在URL中,因此更适合传输敏感信息和大量数据。
2.请求长度限制:
a. GET:由于数据附加在URL上,URL的长度有限制(通常是几千个字符),所以GET请求的数据长度也受到限制。
b. POST:由于数据传输在消息体中,所以可以发送较大的数据量,一般没有长度限制。
3.安全性:
a. GET:因为数据暴露在URL中,所以不适合传输敏感信息,例如密码等。同时,由于参数和值可见,可能会被他人轻易截获。
b. POST:由于数据在消息体中,相对于GET请求更安全,更适合传输敏感信息。
4.请求幂等性:
a. GET:GET请求是幂等的,即对同一个URL的多次请求只会产生一次结果,不会对服务器数据产生影响。
b. POST:POST请求不是幂等的,多次对同一个URL进行POST请求可能会产生不同的结果,因为可能涉及到创建资源或提交数据等操作。
5.请求语义:
a. GET:一般用于获取数据,获取资源,不应该用于对服务器产生影响的操作。
b. POST:一般用于提交数据,创建资源,或者在服务器上执行修改操作。
在实际应用中,我们需要根据具体的业务需求和安全性要求来选择使用GET还是POST方法。如果是获取数据或进行安全性不敏感的操作,可以使用GET;如果是提交敏感信息或进行会改变服务器状态的操作,应该使用POST。